Что такое GC в JVM? алгоритмы работы. Введение.
Сегодня я хочу окунуться в мир сборщика мусора, и рассказать вам о том зачем он нужен? какие алгоритмы используются в JVM для сборки мусора? Как развивались эти алгоритмы от версии к версии и что нас ждет впереди.
Эта тема будет расскрыта в нескольких постах :
-
Введение - что такое сборщик мусора, зачем он нужен и как он понимает что этот объект необходимо удалить из памяти
Что такое GC ?
Если спросить любого технического человека что такое сборка мусора, то он ответит “сбор мусора - это когда операционная среда автоматически освобождает память, которая больше не используется программой. Она делает это путем трассировки памяти, начиная от корня, чтобы определить, какие объекты ещё доступны”[1].
В этом описании перепутаны местами механизм с целью. Это всё равно что сказать, что работа пожарного - “водить красную машину и брызгаться водой”. Это описание того, что делает пожарный, но здесь не указана цель этой деятельности (а именно: тушить огонь, а в общем случае: пожарная безопасность)[1].
Сборка мусора - это эмуляция компьютера с бесконечной памятью. А все остальное это механизмы. “Сбор памяти, которую программа уже не видит” - это один из механизмов. Механизм сборки мусора присутствует во многих современных виртуальных машинах таких как : V8(Javascript), JVM(Java), Parrot(Python), Ruby(YARV) и т.д.
Основной принцип GC это с одной стороны, упростить программирование, избавив программиста от необходимости вручную удалять объекты, созданные в динамической памяти, с другой — устранить ошибки, вызванные неправильным ручным управлением памятью. В основном модуль сборщика мусора включается в состав среды исполнения и запускается в прозрачном для пользователя режиме.
Как разделена памяти в JVM, теория поколений
Память, которая использует JVM, грубо можно разделить на две части : HEAP и (non-heap)STACK.
-
HEAP (куча) - отвечает за рождения и хранения объектов, то есть всех наследников класса Object.
-
STACK - область памяти которая хранит мета информацию о классах(методах), значения примитивных типов, локальные значения потоков и …
В свою очередь каждый участок памяти делиться на более детальные кусочки, которые можно проследить на этом рисунке :

В свою очередь поступает вопрос, зачем нам разделять и разделять память если можно все хранить в одном месте. Есть такая гипотеза(слабая гипотеза), говорящая о том, что большинство новых объектов живут очень не долго, а чем дольше прожил объект, тем выше вероятность того, что он будет жить и дальше. Поэтому разработчиков GC это навело на мысль что в первую очередь необходимо сосредотачиваться на очистке тех объектов, которые были созданы совсем недавно. Именно среди них чаще всего находится бóльшее число тех, кто выжил, и именно здесь можно получить максимум эффекта при минимуме трудозатрат.
Здесь и родилась идея о том что бы разделить память на разные участки : младшее поколение (young generation) и старшее поколение (old generation) и применять к разным участкам памяти разные алгоритмы сборки мусора.
Алгоритмы поиска мертвых объектов
Что бы GC начал свою работу необходимо намусорить, чтобы объект стал доступен для сборки мусора. Доступные объекты в Java это объекты которые не имеют сильных ссылок. В Java для этого мы или присваиваем ссылке null :
Object ref = new Object;
ref = null;
// обьект на который ссылалась ссылка ref теперь доступен сборщику мусораили обьект выходит из своей области видимости :
{
Object ref = new Object;
}
System.out.println(ref); // ошибка компиляции
// обьект на который ссылается ref теперь доступен сборщику мусора,
// потому при выходе программы из фигурных скобок
// обьект становиться недосутпен в дальнейшем коде, поэтому его можно удалитьСуществует два алгоритма для обнаружения мусора:
- Reference counting
- Tracing
Reference counting
Суть подхода заключается в подсчете ссылок. Счетчик хранит сколько ссылок на него указывают и уменьшает свое значение когда ссылка уничтожается, то есть перестает ссылаться на объект.
Главным минусом такого подхода является сложность обеспечение счетчика в многопточной среде, а так же полное отсуствие выявления цыклических связей (когда первый обьект ссылается на второй, а второй ссылается на первый). Такой подход приводит к утечкам памяти что не есть хорошо, поэтому отложим его.
Tracing
Главная идея “Tracing” состоит в том, что живые объекты это те, к которым мы можем добраться из корневых точек, а все остальное мусор. Объекты можно представить как дерево, и нам остается лишь пройтись по дереву (начиная с корневых элементов) и обозначить живых объектов. А не маркированные объекты соответственно будут являться мусором.

HotSpot использует именно такой подход. Но что такое корневые точки ? :
- Локальные переменные и параметры методов
- Статические переменные (метод main)
- Java Потоки
- Ссылки из JNI
Треугольник оптимизации
При определении эффективности работы сборщика мусора можно выделить три фактора:
- Максимальная задержка (Latency) — максимальное время, на которое сборщик приостанавливает выполнение программы для выполнения одной сборки. Такие остановки называются stop-the-world.
- Пропускная способность (Throughput) — отношение общего времени работы программы к общему времени простоя, вызванного сборкой мусора, на длительном промежутке времени.
- Потребляемые ресурсы (Footprint) — объем ресурсов процессора и памяти, потребляемых сборщиком.
На рисунке факторы представлены в виде треугольника :
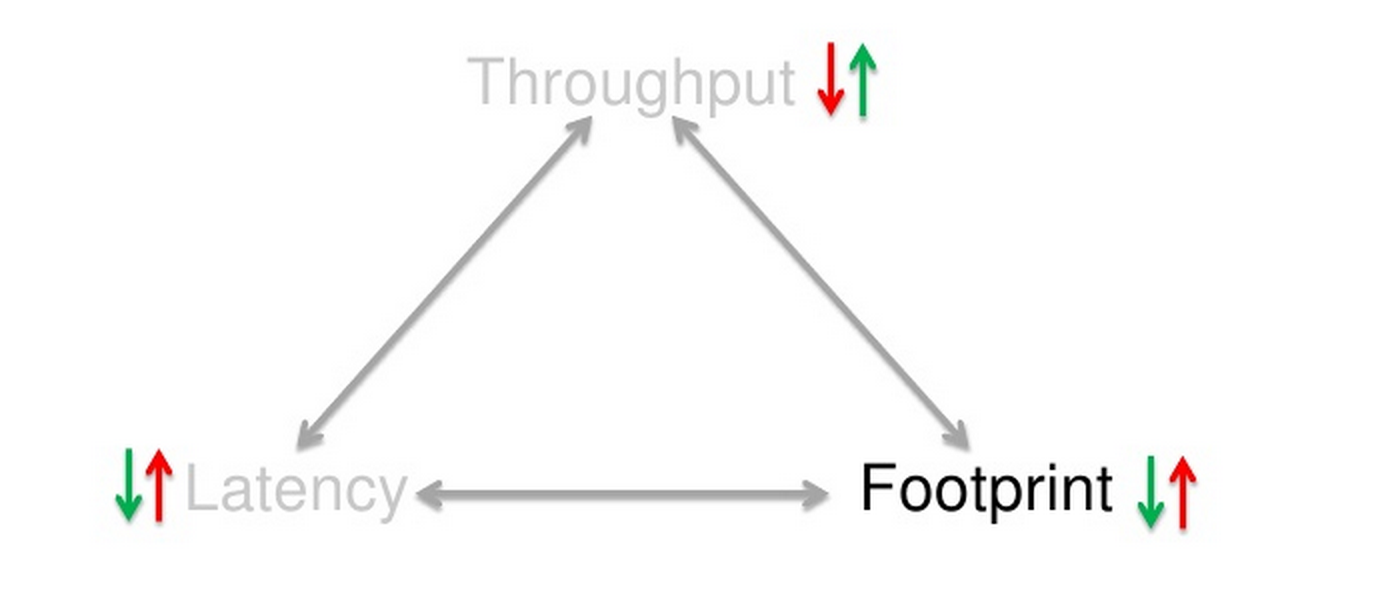
Интересней всего то, что мы можем улучшить только две вершины этого треугольника, то есть потянуть за два угла в ущерб третьему. Например уменьшая потребляемые ресурсы и увеличивая пропускную способность нам необходимо жертвовать временем максимальной задержки что в нашем случаи вырастет.
На данный момент мы знаем что такое мертвые объекты и как их сделать таковыми, а так же знаем как GC их распознает. В следующей статье мы познакомимся с алгоритмами удаления объектов из памяти и как работают разные версии сборщиков мусора.
[1] - http://www.transl-gunsmoker.ru/2012/09/blog-post.html