Алгоритм работы CMS GC, G1 GC. Часть 2.
И на закуску, приглашаю на сцену CMS GC, и его усовершенствованного брата G1.
В этой статье мы рассмотрим два инкрементальных сборщиков мусора CMS и G1, которые нацелены на уменьшение времени SWT пауз, и увеличить производительность для работы с большими объемами в памяти. Но как мы знаем по треугольнику оптимизации, уменьшая время SWT пауз в данном случае жертвовать придется пропускной способностью. Каждый из сборщиков добивается производительности по разному, давайте посмотрим как.
CMS GC
CMS (Concurrent Mark Sweep) - инкрементальный, конкурентный сборщик мусора который появился почти в одно время с Parralell GC. Давайте разберемся, что такое инкрементальный а что такое конкурентный. Инкрементальный означает что сборка мусора, происходит маленькими порциями, во время работы вашего приложения в бэк-граунде, то есть в риал-тайме, в следствии этого, уменьшение STW пауз(к сожалению убрать паузы совсем пока не удалось). И достигается это за счет конкурентных потоков, которые постоянно хотят найти и убрать мусор. Я думаю всем знакомый случай, когда вы сидите за завтраком в закусочной, а к вам постоянно пристает уборщица и просит убрать ноги что бы помыть полы. Подобным образом работает и CMS, вы едите, а вас периодически, и вроде бы не навязчиво, подметают или моют полы.
Как включить : -XX:+UseConcMarkSweepGC.
Принципы работы
Начнем с того что мы уже знаем. Этот сборщик мусора использует то же разделение памяти что и предыдущих два - Edem, S-0, S-1, Tunered. Его цель решить проблему долгих пауз. Как правило эти паузы очень хорошо заметны в старшем поколении, так как оно значительно больше по размерам чем младшее, соответственно отслеживание и чистка мертвых объектов по времени больше. Поэтому разработчики пошли путем улучшения именно сборки мусора в старшем поколении.
В младшем поколении работает все тот же minor цикл, а со старшим поколением работает так называемый major цикл(не путать с полным циклом), который нацелен на оперирование только старшим поколением. К тому же Tunered поколению не обязательно быть до конца заполненным, что бы запустился major цикл, вся работа происходит во время работающего приложения.
Давайте детально рассмотрим это цикл.
Начинается все с короткой остановки программы для пометки так называемых корневых объектов. После клиентская программа возобновляется, и параллельно с ней запускается один(несколько) потоков, который индексирует живые объекты используя корневые точки.
Конечно куча не постоянна, и за время работы программы, некоторые индексы стали не актуальны, поэтому происходит еще одна остановка, для повторного сканирования/индексирования объектов.
После программа возобновляется и сборщик производит очистку памяти от мертвых объектов в нескольких параллельных потоках. Но есть один нюанс, после очистки объектов из старшего поколения, упаковка(сжатие) происходить не будет, так как это проблематично осуществить во время работающего приложения, поэтому со временем память становиться фрагментированной. В связи с этим GC должен поддерживать особый список с хранением адресов участков свободной памяти (free lists). То есть при создании нового объекта, необходимо обойти этот список, что накладывает дополнительные ресурсы. Поэтом создание объекта дорогостоящая операция данном сборщике мусора.
Так же это сборщик мусора имеет интеллект и проявляется он в сборке статистики по SWT между major и minor циклами и пытается оптимизировать их во времени (разнести), что бы предотвратить скопление пауз в одном промежутке времени.
Но что если сборщик мусора не успевать очистить Tunered область, в этом случаи приложение приостанавливается и запускается сборка в последовательном режиме. Такая ситуация называется - concurrent mode failure, то есть сбой конкурентного режима.
Плюсы и минусы
Как было описано выше, это конкурирующий, инкрементальный сборщик мусора, нацеленный на минимизацию простоя приложения. Для некоторых приложений это является критическим фактором. И так как он работает в фоновом режиме, пропускная способность самого приложения немного падает, так как и приложение, и сборщик мусора, будут конкурировать за ресурсы. Так же отсутствие уплотнения(сжатия) фрагментирует память, что заставляет нас выделять больше памяти (20-30 %) для этого.
Но такой сборщик может подойти приложениям, использующим большой объем долгоживущих данных. В этом случае некоторые его недостатки опускаются.
Настройка
Те же настроки что и в Parralell GC.
-XX:CMSInitiatingOccupancyFraction=? - пороговое значение наполения Tunered области, для запуска цикла полной сборки мусора
G1 GC
G1 (Garbage First) - один из молодых(последних) сборщиков мусора. Он не является наследником предыдущих GC, он не добавляет еще параллельности или конкурентности, он не разбивает на еще большее количество областей память, он кардинально меняет подход к самой сборке.
Это самый первый конкурент CMS GC, который позиционирует себя как сборщик мусора для работы с большими кучами ( > 4Гб) для которого важна сохранность времени отклика и предсказуемость. Компания Oralce хочет выдвинуть его как стоящую замену CMS и поставить его стандартным сборщиком мусора для серверных конфигурация в 9-й версии.
Как включить : -XX:+UseG1GC
Принципы работы
Первое что бросается к глаза, так это организация кучи. Здесь память разбивается на множество участков от 1-32 Мб, и каждый из этих участков можеть быть как и Edem, S-0, S-1 так и Tunered. Исключением лишь являются громадные участки (humongous), которые создаются объединением простых регионов.
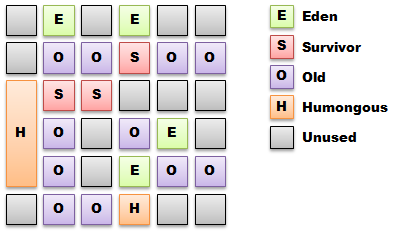
Малые сборки работаю с младшими поколениями, и выполняются они периодически, все так же для переноса выживших из Edem в S-0, S-1 или Tunered. Никуда нам не деться от SWT пауз, которые присутствуют и здесь, но есть кардинальное отличие, сборщик мусора сам решает над каким из младших поколений ему работать, исходя из заданного времени и максимально выгодного результата. Поэтому его и прозвали Garbage First - то есть - мусор превыше всего.
Работа со старшим поколением называется смешанным циклом, и она так же отличается от CMS маленькой особенностью. В G1 существует процесс, называемый циклом пометки (marking cycle), который работает параллельно с основным приложением и составляет список живых объектов. Подобный процесс присутствует и в CMS, но немного отличается в конце.
- Маркировка корневых объектов полученных из малых циклов (Initial mark), остановка приложения
- Параллельная пометка живых объектов (Concurrent marking), во время работающего приложения
- Остановка приложения и повторный поиск неучтенных объектов (Remark)
- Очистка от мусора при остановленном приложении, поиск пустых регионов для новых объектов параллельно с работающим приложением
После G1 переключается в режим смешанной сборки. Это означает, что к младшим регионам, подлежащим очистке, подселяют некоторое количество из старшего региона. Делается это для того что бы оптимизировать и уложится в заданное время сборки, а размеры подселяемых участков и их количество коррелируется статистикой собранной на предыдущих циклах. После того как GC собрал достаточно мусора, он переключается в режим малой сборки.
Может произойти ситуация, что в процессе очисти не останется памяти для винивших объектов, в таком случаи запускается полный сборщик мусора и приложение приостанавливается.
Следует упомянуть о гигантских объектах (humongous objects) - те которые не помещаются в один регион. Обработка этих объектов следует таким правилам : - такой объект никогда не копируется/перемещается между регионами - он может быть удален как во время цикла маркировки, так и во время цикла очистки - к таким регионам никогда никого не подселяют
Плюсы и минусы
Цель этого сборщика мусора сделать эти сборки настолько предсказуемыми насколько возможно. Так же он решает проблему фрагментации памяти. Конечно же что бы всего этого достичь, необходимо жертвовать пропускной способность(нагрузкой на CPU). На данном этапе я думаю это достойная замена CMS для северных приложений, а так же как плацдарм для экспериментов.
Настройка
- -XX:ParallelGCThreads=? - количество потоков для сборки мусора
- -XX:ConcGCThreads=? - количество потоков для цикла пометок
- -XX:G1HeapRegionSize=? - размер области региона
Вот мы и познакомились со всеми сборщиками мусора в виртуальной машине HotSpot. Надеюсь эти статьи пролили свет на многие аспекты работы GC а так же добавило понимая, что же там все таки твориться под капотом.
В следующей статье я расскажу, какие есть проблемы у JVM (OutOFMemory etc), как их можно решать, и какие есть способы трекинга и оптимизации JVM.