Anatomy of a Program in Memory [Перевод]
Что бы стать хакером мало знать языки программирования, необходимо разбираться как все устроено, вплоть до бегущих электронов в проводнике.
Данный пост является свободным переводом статьи Anatomy of a Program in Memory
Управление памятью является сердцем операционной системы : и это важно помнить как и программистам, так и администраторам. Так как рассказ будет общего характера, примеры будут приводиться на linux и windows 32/64-bit системах.
Каждый процесс в многозадачной ОС выполняется в собственной “песочнице”, то есть в виртуальном адресном пространстве. Соответствие между виртуальным пространством и физической памятью описывается с помощью таблицы страниц (page table), которые обслуживаются ядром операционной системы и центральным процессором. Важно помнить, что эта концепция распространяться на все запущенное ПО, включая ядро.
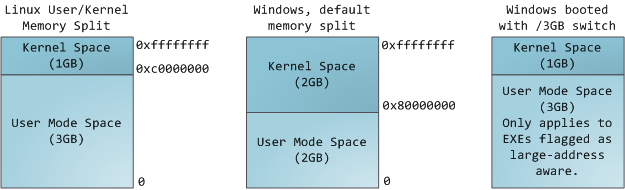
Как видно из рисунка, ядро так же занимает свою “песочницу” и в простом user mode режиме мы обращаться к нему мы не можем, сразу же вылетает page fault ошибка. В Linux пространство памяти для ядра присутствует постоянно, и ставит в соответствие одну и ту же часть физической памяти у всех процессов, так что любая программа/процесс может ссылаться на него, при необходимости обработать прерывание или системный вызов.
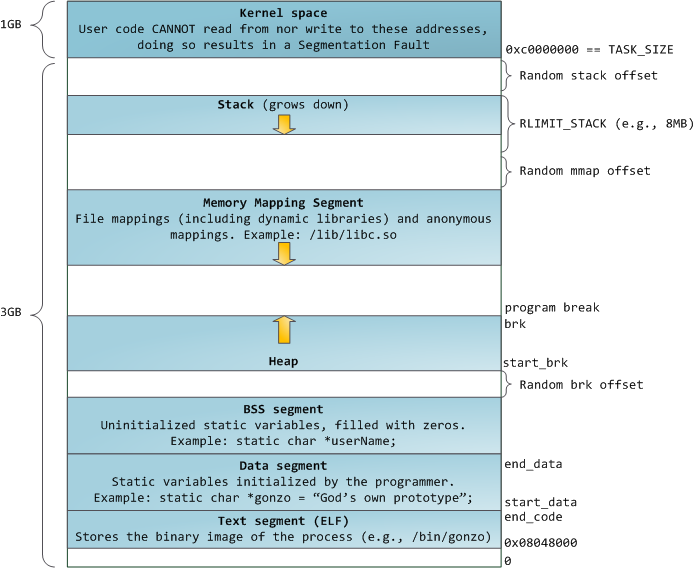
Каждый процесс делит песочницу на определенные сегменты :
- стек (Stack)
- куча (Heap)
- BSS
- сегмент данных (Data Segment)
- сегмент текста программы (Text Segment)
Стек (Stack)
Самый верхний сегмент адресного пространства это стек, который хранит локальные переменные и параметры функций в большинстве языков программирования. Вызов метода или функции толкает новый кадр стека в стек. Кадр стека разрушается, когда функция вызывает return (возвращает управление). Данные в стеке обрабатываются в соответствии с принципом «последним пришел — первым обслужен» (LIFO). Поэтому, для отслеживания содержимого стека достаточно знать лишь положение указателя на вершину стека. Добавление данных в стек и их удаление – операция быстрая. Кроме того, многократное использование одних и тех же областей стека приводит к тому, что они помещаются в кеш процессора, что еще более ускоряет доступ к ним. Каждый поток в процессе имеет свой собственный стек.
Стек может исчерпать свои объемы добавляя в него больше данных, чем он может обработать. Это вернет нам ошибку страницы памяти, которая в Linux может быть обработана командой expand_stack(), который в свою очередь вызывает acct_stack_growth(), что бы проверить на возможность увеличения стека. Если размер стека ниже RLIMIT_STACK (обычно 8 Мб), то, как правило, стек растет и программа продолжает весело работать. Это нормальный механизм, посредством которого размер стека регулируется по требованию. Тем не менее, если был достигнут максимальный размер стека, мы получим переполнение стека и программа вернет ошибку сегментации(Segmentation Fault). В то время, когда область стека расширяется в памяти в зависимости от требований, она никогда не будет сжиматься, становиться меньше.
Только рост стека может задействовать свободные участки памяти. Любое другое обращения к не отображенным (unmapped) участкам памяти обрабатывается как ошибка. Некоторые участки памяти могут быть помечены как read-only, поэтому попытка изменить их может привести так же к ошибке.
Куча (heap)
Куча используется для выделения памяти во время выполнения программы, как и стек. Но, в отличии от стека, память, выделенная в куче, сохраняется и после того как функция, вызвавшая выделение этой памяти, завершит работу. Большинство программ предоставляют управление кучей автоматическим сборщикам. Язык С дает программисту целый ряд средств управления памятью в куче. Например, в языке С функция malloc() выделяет память, а free() - освобождает ее. В других языках Java, C# работает автоматический сборщик мусора, что снимает с разработчиков отвесвтенность подчищать памяти вручную.
так же можно написать свою реализацию методов malloc и free и внедрить их использование вместо стандартных алгоритмов в ядро linux - http://habrahabr.ru/post/270009/
Если в куче достаточно места, что бы удовлетворить запросы программы, то это может быть обработано постсредствами самого языка, без участия ядра ОС. В противном случае куча увеличится вызовом brk(), что бы освободить место для запрашиваемого блока. Управление кучей - сложная, комплексная задача, которая направлена на решение эффективного и быстрого выделения памяти, удовлетворяя потребности разработчиков. Время для обслуживания кучи может существенно различаться. Системы реального времени (real-time system) имеют специальные алгоритмы - special-purpose allocators для решения таких проблем. Порой куча может прийти к фрагментированому состоянию :

BSS, Data, Текст программы (Program text)
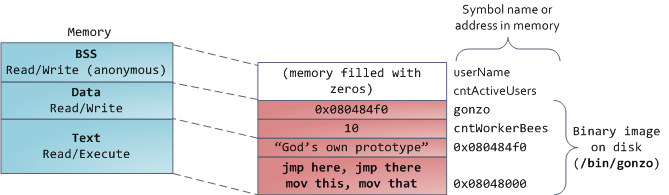
Наконец мы добрались до самых низких сегментов памяти: BSS, Data и текст программы. BSS и Data хранят данные о статических (глобальных) переменных языка C. Различие состоит в том, что BSS хранит не инициализированные переменные, то есть те, которые не были выставлены в исходном тексте программы. Если мы присвоим переменной int cntActiveUser модификатор static, то он попадет в эту область.
В другом случае Data сегмент хранит статические переменные, которые уже были инициализированны в коде. Эта область не является анонимной. Например static int cntWorkerBees = 10 попадет в эту область.
На представленном ниже рисунке, указатель на gonzo (4-bite) поселился в сегменте данных (Data segment). Однако, строка “God’s own prototype” будет находиться в сегменте текста программы (text segment, program text segment), который используется в режиме только для чтения и хранит исходный код программы.
Мы можем посмотреть как используются области памяти процесса, прочитав содержимое файла /proc/pid_of_process/maps. Так же мы можем изучить бинарные исполняемые образы используя инструменты nm и objdump для символьного предоставления адресов, сегментов и т.д. Nm и objdump входят в состав комплекта утилит обработки двоичных файлов GNU binutils.
Данный пост дает лишь базовые понятия о том, из чего состоит исполняемая программа и как ядро размещает ее в памяти. А зная расположение сегментов в памяти можно : как и написать эксплоит (для передачи управления), так и обезопасить свою программу от уязвимых мест.
Ссылки :